Continuando con nuestra serie de artículos de Problemas de Rendimiento en SQL Server relacionados con los eventos de traza Hash Warning y Sort Warnings, y después de explicar la relación entre los Memory Grants y los eventos Sort Warning/Hash Warnings, llega el momento de mostrar un ejemplo paso a paso a través del cual vamos a reproducir un evento Sort Warning y vamos a comprobar como la ocurrencia de dicho evento implica un coste adicional de acceso a TEMPDB (spilling to TEMPDB) debido a la subestimación de memoria de consulta (representada por el evento Sort Warning). Seguidamente vamos a reproducir el caso contrario, es decir, una sobrestimación de memoria de consulta (Query Memory o Workspace Memory), que como comentamos en artículos anteriores, también resulta un problema aunque no se represente mediante eventos Sort Warning ni Hash Warning.
Téngase en cuenta que en el presente artículo vamos a reproducir un evento Sort Warning como resultado de la reutilización del Plan de Ejecución. Sin embargo, este evento puede ocurrir por diferentes motivos. Otro posible caso sería la ocurrencia del evento Sort Warning por la existencia de estadísticas incorrectas o poco actualizadas.
Preparando el entorno de Laboratorio
Partimos de una instancia SQL Server 2008 R2, con la base de datos de Adventure Works instalada. Para nuestro ejemplo, hemos creado un índice sobre la tabla que deseamos consultar, que eliminaremos al finalizar nuestras pruebas. Seguidamente hemos creado un procedimiento almacenado (dbo.SalesOrderSelect), el cual devuelve un conjunto de filas ordenadas (ORDER BY), filtrando por un rango de fechas (BETWEEN) que se especifican como parámetros de entrada de dicho Procedimiento Almacenado. Bueno, aunque parece todo muy abstracto, no os preocupéis, ya que al final del artículo podéis descargar el Script SQL con todo el código de ejemplo (eso sí, tendréis que tener instalada previamente la base de datos de Adventure Works).
Este es un ejemplo muy representativo, ya que en función de los valores de los parámetros de entrada, el número de filas afectadas será mayor o menor. Dado que estamos utilizando un ORDER BY, esto impactará en las necesidades de memoria para ejecutar el Sort (Memory Grant), y de aquí, que puedan producirse eventos Sort Warning con cierta facilidad al intentar reutilizar un Plan de Ejecución. Insisto, esto es muy representativo, porque es exactamente lo mismo que ocurre en muchas empresas.
Para continuar, deberemos abrir el SQL Profiler, y ejecutar una traza para capturar las ocurrencias de los siguientes Eventos (a esto es lo que se llama "la prueba del algodón" ;-)
- Errors and Warnings - Hash Warning
- Errors and Warnings - Sort Warnings
- Stored Procedures – SP:CacheHit
- Stored Procedures – SP:CacheInsert
Reducimos TEMPDB al menos tamaño posible. En nuestro caso de ejemplo, el MDF de TEMPDB ocupa tan sólo 1,5MB.
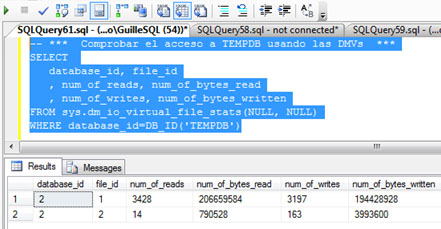
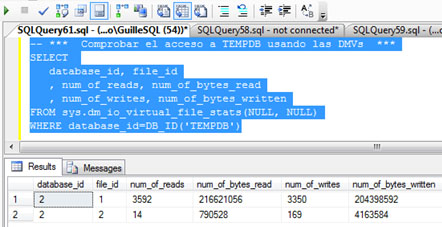
Además, vamos a consultar la DMV sys.dm_io_virtual_file_stats, para identificar las lecturas y escrituras realizadas sobre TEMPDB, y de este modo, poder tener otra medida que nos indique si se ha incurrido en un acceso a TEMPDB o no. En la siguiente pantalla capturada se muestra la consulta realizada y la salida obtenida.
Ejecución de las Pruebas para reproducir el evento Sort Warning
Ya tenemos preparado nuestro entorno. Así que, a continuación vamos a empezar las pruebas para reproducir las subestimación de memoria de consulta (con el correspondiente evento Sort Warning) y la sobrestimación de memoria de consulta, ocasionada por la reutilización de Planes de Ejecución.
IMPORTANTE: para conseguir reproducir la reutilización del Plan de Ejecución es importante realizar las diferentes invocaciones al procedimiento almacenado, lo más seguidas posibles. Del mismo modo, pare reproducir la generación de un nuevo Plan de Ejecución, podemos esperar unos minutos antes de volver a invocar al procedimiento almacenado. Si no lo hacemos así, no conseguiremos reproducir los pasos descritos en este artículo. Al margen, recordemos que en la realización de este tipo de pruebas, podemos apoyarnos en DBCC FREEPROCCACHE, para vaciar la caché de procedimientos de almacenados. Dicho todo esto, empezamos.
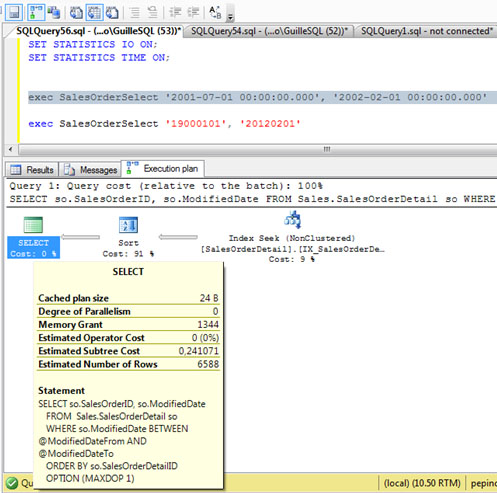
Vamos a ejecutar nuestro Procedimiento Almacenado de ejemplo para un rango de fechas pequeño, con la opción Include Actual Execution Plan habilitada, tal y como se muestra en el siguiente ejemplo. Como podemos observar, el valor de Memory Grant es 1344.
Si nos fijamos en la operación SORT, el número de filas estimadas y el número de filas actuales (afectadas) es coincidente, por lo que podemos entender que la concesión de memoria para esta consulta (Memory Grant) es apropiada. De hecho, en nuestra traza de SQL Profiler, no se muestra ningún Sort Warning.
Por supuesto, TEMPDB no ha crecido. Las operaciones que ha necesitado realizar nuestra consulta SQL, se han realizado en memoria RAM (Query Memory o Workspace Memory), como Dios manda.
Ejecutamos de nuevo el mismo procedimiento almacenado para los mismos valores de entrada, y al volver a examinar el Plan de Ejecución, obtenemos de nuevo las mismas conclusiones. Todo bien. Es como debe ser.
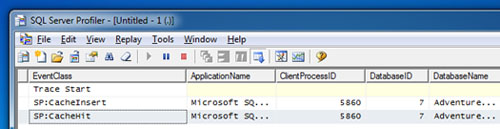
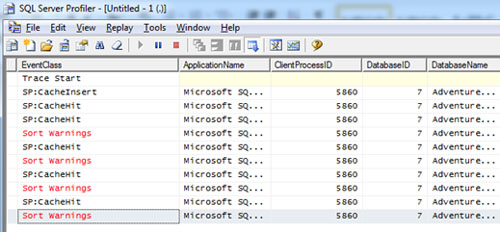
Si nos fijamos en la traza que tenemos corriendo, en la primera ejecución se cacheo el Plan de Ejecución en Memoria (CacheInsert), y en la segunda ejecución se reutilizó el Plan de Ejecución (CacheHit). Como dije antes, la prueba del algodón ;-)
Además, si volvemos a consultar la DMV sys.dm_io_virtual_file_stats, podemos observar que no se ha producido ninguna lectura ni escritura sobre TEMPDB.
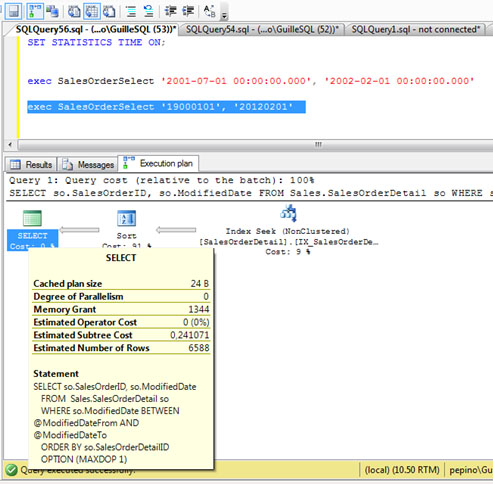
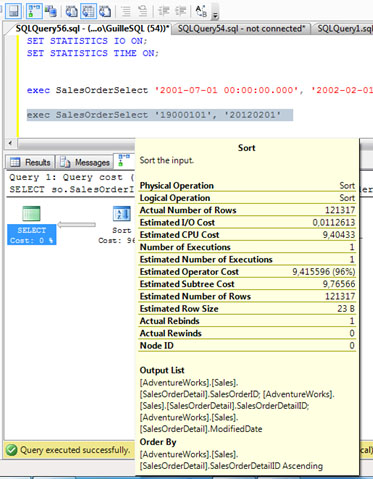
Ahora, vamos a ejecutar el mismo procedimiento almacenado con unos valores de entrada distintos, que seleccionen un conjunto de filas mucho más grande, como se muestra en la siguiente pantalla capturada. Al revisar el Plan de Ejecución, sorpresa: Estamos reutilizando el mismo valor de Memory Grant de la anterior ejecución, de hecho, el número de filas estimado es también el mismo de la anterior ejecución.
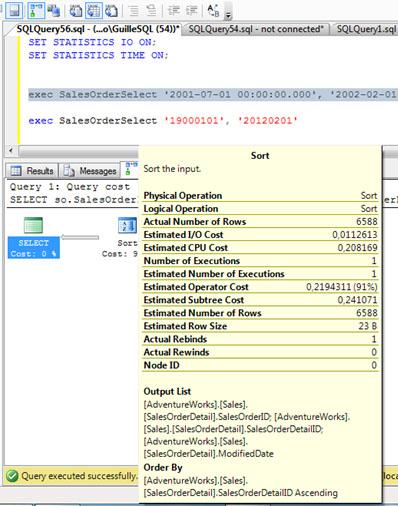
Si revisamos los detalles de la operación SORT en el Plan de Ejecución, podemos observar que el número de filas estimadas y actuales (afectadas) es totalmente distinto. Vaya, ¿fallo de estimación, o reutilización del Plan de Ejecución?
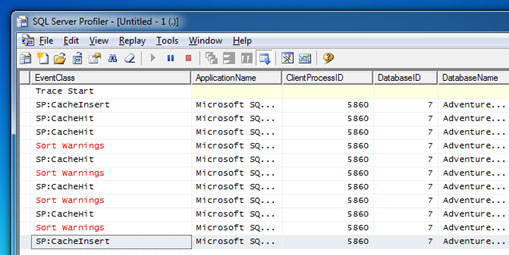
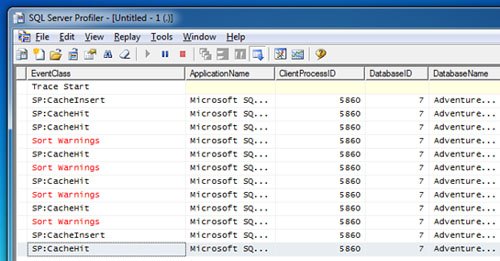
Si revisamos la traza que SQL Profiler que iniciamos antes, zas: se ha producido un evento Sort Warning. En la siguiente pantalla capturada, se muestra la traza de SQL Profiler, después de ejecutar cuatro veces el procedimiento almacenado con el nuevo (amplio) rango de valores pasado como parámetros, con los correspondientes Sort Warning. Como se puede apreciar, se está reutilizando el Plan de Ejecución (CacheHit), y debido a la subestimación de memoria se produce el Sort Warning. Más claro, agua.
Otro tema. Al revisar la salida de Mensajes de la ejecución (si activamos las opciones SET STATISTICS IO y SET STATISTICS TIME), podemos comprobar que no se ha creado ninguna Tabla de Trabajo (Work Table) en TEMPDB, por lo que, podríamos pensar que no ha sido necesario incurrir en un acceso a disco adicional a TEMPDB para poder procesar esta consulta.
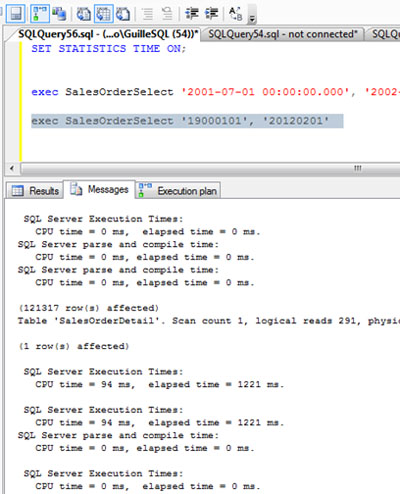
Sin embargo, TEMPDB ha crecido para poder procesar esta consulta en unas condiciones de subestimación de memoria, como se puede observar en la siguiente pantalla capturada. Por lo tanto, esta ejecución ha sido más costosa que las dos anteriores, ya que al margen de procesar un mayor número de filas, ha requerido del crecimiento de TEMPDB y del acceso (R/W) a TEMPDB para poder realizar el SORT, en una condiciones ínfimas de memoria. Este comportamiento se denomina desbordamiento sobre TEMPDB (spilling to TEMPDB), que no debe confundirse con las Tablas de Trabajo (Work Tables). Son accesos a TEMPDB completamente distintos, que no debemos confundir.
Además, si volvemos a consultar la DMV sys.dm_io_virtual_file_stats, podremos comprobar que en esta ocasión sí se han producido lecturas y escrituras sobre TEMPDB, consecuencia del desbordamiento sobre TEMPDB (spilling to TEMPDB) que comentábamos.
Un rato más tarde, volvemos a ejecutar de nuevo nuestro procedimiento almacenado con el mismo amplio rango de valores. En esta ocasión, se ha creado un nuevo Plan de Ejecución (CacheInsert), utilizando unos valores de entrada correspondientes a un amplio rango de filas (los utilizados en la ejecución actual), y en consecuencia, no se ha producido ningún Sort Warning, por lo que esta ejecución no ha requerido acceso a TEMPDB (al menos, no se ha producido spilling to TEMPDB).
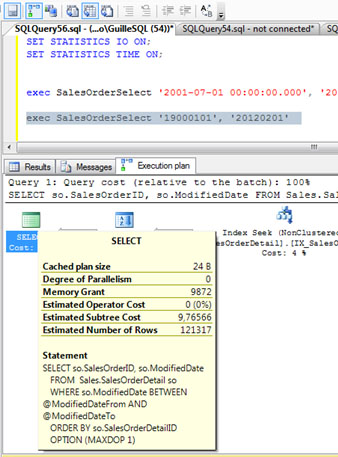
Si miramos el Plan de Ejecución, veremos que en esta ocasión el valor de Memory Grant es de 9872, y el número de filas estimadas es de 121317.
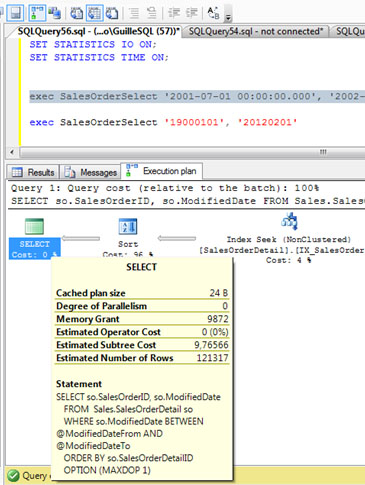
Del mismo modo, si revisamos el operador SORT del Plan de Ejecución, podemos comprobar que el número de filas estimadas y actuales coincide. Genial.
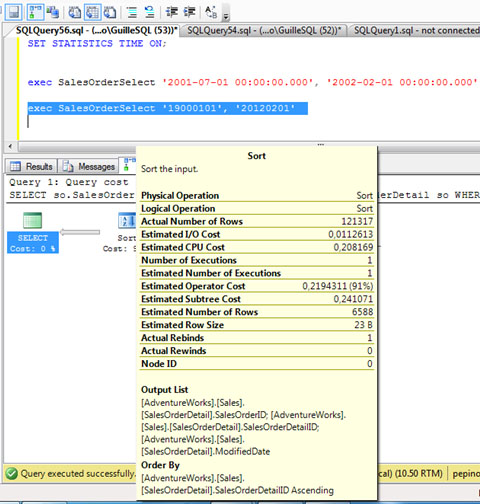
Ahora que tenemos cacheado en memoria el Plan de Ejecución para unos valores de entrada que afectan a un amplio rango de filas, vamos a ejecutar de nuevo el procedimiento almacenado con unos valores de entrada que afecten a un pequeño rango de filas (recordemos, la primera ejecución que hicimos). En esta ocasión se va a reutilizar el Plan de Ejecución (CacheHit), sin embargo, la estimación de uso de memoria de consulta en esta ocasión va a ser mucho mayor de la que realmente se necesita, es decir, vamos a desperdiciar gran parte de la memoria RAM que se va a asignar a esta ejecución (Sobrestimación). En este escenario, no se va a acceder a TEMPDB (no hay spilling to TEMPDB), lo cual puede parecer que no tenemos ningún problema de rendimiento, pero al desperdiciar memoria, podemos encontrarnos con consultas encoladas (que estén sufriendo esperas – Waits) pendientes de que las asignen memoria de consulta (Query Memory) para poder ejecutarse, por estar gran parte de la memoria de consulta asignada (aunque no se esté utilizando, por la sobrestimación de memoria). A continuación se muestra de nuevo un pantallazo de la Traza. Cristalino.
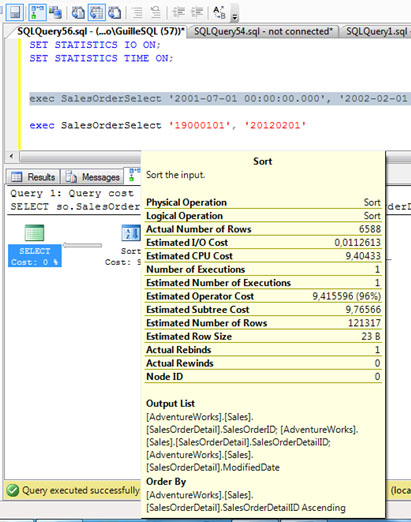
Como soy muy judas, he obtenido el Plan de Ejecución de esta última invocación, para así poder ver las cosas aún más claras (si cabe). Como se aprecia en la siguiente pantalla capturada, esta última ejecución se ha utilizado un Memory Grant de 9872 (en lugar de 1344, que es el valor que le correspondería para la cantidad de filas afectadas), y el número de filas estimas es de 121317 (en lugar de 6588).
Para más detalles, a continuación se puede ver la información contextual del operador SORT en el Plan de Ejecución. Ojo en la diferencia existente entre el número de filas estimadas y actuales (está claro: hay sobrestimación).
Conclusiones y Script SQL de ejemplo
Como hemos podido ver, la reutilización de Planes de Ejecución puede provocar problemas de subestimación de memoria de consulta, lo cual, implicará una pérdida de rendimiento por la utilización de TEMPDB (acceso a disco, ese gran enemigo de las bases de datos, provocado por el spilling to TEMPDB), y quedará evidenciado por la aparición de eventos de traza Sort Warnings.
Adicionalmente, la existencia de este tipo de problemas puede implicar que también suframos problemas de sobrestimación de memoria, que sin ser tan claramente identificables (no hay eventos Sort Warning asociados), no deja de ser un problema, que nos puede generar esperas (Waits) en nuestras consultas para obtener memoria, a la vez que estamos despilfarrando RAM. No mola.
Como veremos en el próximo artículo Hash Warnings, TEMPDB, y el Plan de Ejecución: Ejemplo práctico, existe más efectos colaterales de la reutilización de Planes de Ejecución y los eventos Hash Warning / Sort Warning, como es el caso de reutilizar un Plan de Ejecución con Operadores no óptimos.
No podía faltar el Script SQL de ejemplo utilizado para la redacción del presente artículo.
Poco más por hoy. Como siempre, confío que la lectura resultase de interés.