SQL Server 2012 AlwaysON Availability Groups (AG) es capaz de juntar las tecnologías de Database Mirroring (DBM) y Windows Server Failover Cluster (WSFC), y obtener lo mejor de ambos mundos: una nueva tecnología de Bases de Datos en Alta Disponibilidad, que casi deberíamos llamar SuperMirror ó CachoMirror. Jeje ;-)
La configuración de AlwaysON Availability Groups sobre SQL Server 2012 requiere previamente de la instalación de un Failover Cluster, como paso previo requerido. Sin embargo, no se trata de una instalación típica, ya que dispondremos de diferentes alternativas de diseño, pudiendo utilizar discos locales y/o discos compartidos (incluyendo Almacenamiento Asimétrico), pudiendo realizar instalaciones de SQL Server 2012 en Cluster (Failover Cluster Instance - FCI) o en Standalone, más las propias configuraciones del AlwaysON Availability Groups. En este aspecto, resulta un cambio de diseño más que sorprendente, en comparación con las versiones anteriores de SQL Server, que llega incluso a resultar bastante confuso en la primera toma de contacto con AlwaysON, pero que finalmente acaba siendo muy fácilmente entendible, sensato, potente, y sobre todo divertido.
Alta Disponibilidad (HA) y Recuperación ante Desastre (DR)
Dos términos de los que hablaremos bastante junto con AlwaysON Availability Groups son HA y DR, por lo que antes de continuar con nuestro camino, vamos a hacer un kit-kat para introducir ambos conceptos, y evitar confusiones innecesarias desde un principio.
- Alta Disponibilidad (High Availability – HA). Se refiere a la Tolerancia a Fallos, es decir, a la recuperación rápida del servicio en caso de fallo, evitando una indisponibilidad.
- Recuperación ante Desastre (Disaster Recovery – DR). Se refiere a la capacidad de recuperar el servicio ante una situación de desastre, quizás en un CPD Secundario, incluso asumiendo que el CPD Principal se ha perdido definitivamente.
Dicho esto, parece que ambos términos se refieren a lo mismo, pero existe cierto matiz. Pongamos un ejemplo para aclararlo:
- Si montamos una Instancia de SQL Server en un Cluster con dos Nodos en un mismo CPD, estaremos ofreciendo una solución de Alta Disponibilidad (HA), ya que ante la pérdida de uno de los Nodos, podremos continuar ofreciendo el servicio desde el otro Nodo. Y si además, existen múltiples caminos de red (Ethernet) y de almacenamiento (SAN), y la cabina de discos está replicada, pues mejor. Suele implicar la posibilidad de un Failover Automático. Sin embargo, ante una situación de desastre (ej: un desastre natural que arruine nuestro preciado CPD), estaríamos totalmente desprotegidos: tenemos todos los huevos en la misma cesta. No hay DR.
- Si montamos una segunda Instancia de SQL Server en otro CPD (indiferentemente de que la montemos en Cluster o Standalone), y establecemos un Database Mirror (DBM) para cada BBDD, estaremos ofreciendo una solución de Recuperación ante Desastres (DR). En este caso, ante un desastre producido en el CPD Principal, podríamos ofrecer el servicio desde el CPD Secundario, aunque quizás necesitemos realizar alguna acción manual para completar correctamente el Failover (ej: cambiar las Cadenas de Conexión de alguna aplicación). Este tipo de solución se denomina FCI+DBM (Failover Cluster Instance + Database Mirroring).
Por poner otro ejemplo, podríamos tener montada una Instancia de SQL Server en un Cluster de dos Nodos, con cada Nodo en un CPD distinto (con una solución de Almacenamiento Compartido, Simétrico y Replicado entre CPDs), ofreciendo de este modo una solución de HA y DR. Este tipo de escenarios es bastante típico (al menos para mí, que trabajo en un entorno así todos los días desde hace unos años ;-), y en muchos casos suele montarse junto con alguna tecnología de Extensión de VLANs (stretch VLAN), de tal modo que la misma VLAN esté presente en ambos CPDs. En cualquier caso, se trata de una solución bastante cara (licencias del Almacenamiento Compartido y Replicado, Extensión de VLAN, más el resto de HW, SW, y Comunicaciones… una pasta…), y además el canuto que une ambos CPDs en ocasiones puede hacer de cuello de botella, añadiendo latencias.
Otro punto a recalcar: cuando hablamos de una Instancia en Cluster, estamos hablando de HA y/o DR a nivel de toda la Instancia, mientras que cuando hablamos de Database Mirroring estamos hablando de HA y/o DR a nivel de Base de Datos.
Antes de pasar al siguiente tema, es muy importante recordar que independientemente de las soluciones de HA y DR que usemos, deberemos seguir haciendo Backups. Sin Backups, no hay paraíso.
AlwaysON Availability Groups (AG)
AlwaysON nos permite poder definir Grupos de Disponibilidad (Availability Groups – AG), formados por una o más Bases de Datos, que pueden ser sincronizadas entre varias instancias, de tal modo, que pueda realizarse una sincronización síncrona (para propósitos de HA, con el correspondiente coste de Latencia por Transacción) o una sincronización asíncrona (para propósitos de DR).
El concepto de Réplicas dentro del contexto de AlwaysON, es similar al Database Mirroring (DBM), sólo que incluye varias diferencias y mejoras, que hace que podamos incluso denominarlo Mirror 2.0 ó SuperMirror:
- Grupos de Disponibilidad (Availability Groups – AG). Podemos crear uno o varios Grupos de Disponibilidad, cada uno de los cuales puede incluir una o varias Bases de Datos, de tal modo que el balanceo (Failover) de las mismas se realice de todas las bases de datos a la vez. Cada Grupo de Disponibilidad se materializará en un Grupo de Recursos del Failover Cluster.
- Es posible definir hasta cinco réplicas en cada Grupo de Disponibilidad, una réplica principal (accesible en modo lectura/escritura) y hasta cuatro secundarias.
- Sólo podemos crear la Réplicas en Instancias SQL Server que se estén ejecutando en Nodos del mismo Failover Cluster (Standalone o FCI), no siendo posible entre Instancias miembros de Cluster distintos.
- Es posible configurar una o varias réplicas secundarias como accesibles en modo sólo lectura, de forma que se puedan utilizar para ejecutar informes, realizar descargas de datos, etc., descargando de trabajo a la réplica principal. Téngase en cuenta que la carga de trabajo de sólo-lectura realizada con las Instancias Secundarias utilizarán de forma implícita (y automática) el Modo de Aislamiento de Versionado de Filas (Row Versioning), de tal modo que se minimicen los bloqueos que podrían ocurrir al aplicar las transaccinoes provenientes del Principal (escrituras) con las lecturas que se estén produciendo en el Secundario.
- Es posible utilizar las réplicas secundarias para realizar Backups desde ellas, de tal modo, que se libera de la carga de trabajo de los Backup a la réplica principal, teniendo en cuenta que sólo estarán permitidos los Backups de LOG y los Backups FULL WITH COPY_ONLY, es decir, no podremos realizar Backups FULL convencionales ni Backups Diferenciales (estos sólo los podremos realizar desde la Instancia que actúe como Principal).
- Es posible crear un Listener en cada Grupo de Disponibilidad, de tal modo, que los usuarios puedan conectarse utilizando los datos de conexión de dicho Listener, independientemente de qué Instancia esté actuando de Principal. Esto es posible porque cada Listener se materializará en un Recurso de Nombre con un Recurso de IP asociado (con el correspondiente registro Alias en DNS y la correspondiente Cuenta de Equipo en Directorio Activo), dentro del Grupo de Recursos correspondiente a dicho Grupo de Disponibilidad.
- Si utilizamos una Instancia de SQL Server en Cluster (FCI) como Principal, estaremos condicionados a utilizar un Failover Manual. Esto es By Design: FCI nos dará el HA, mientras que AlwaysON nos dará DR.
- Todas las Instancias en Cluster (FCI) deben tener Nombres de Instancia distintos (ej: no podemos tener dos Instancias por Defecto en el mismo Cluster). Bueno, esto realmente nos debe de dar igual, ya que podemos utilizar los Listener para abstraernos de este tipo de detalles.
- A diferencia de Database Mirroring (DBM), en AlwaysON no existe el rol del árbitro (Witness).
Por lo demás es muy parecido al Database Mirroring (DBM), pues deberemos configurar nuestras Bases de Datos en Modo de Recuperación Completo, podremos configurar las réplicas como síncronas o como asíncronas, etc.
Realizada esta explicación, surge la siguiente duda: Entonces ¿Para qué queremos el Database Mirroring en SQL Server 2012? Pues por ejemplo como soporte de HA y/o DR entre instancias de SQL Server que no pertenezcan al mismo Failover Cluster (o que no pertenezcan a ningún Cluster en absoluto).
Failover Cluster y AlwaysON Availability Groups: vaya par de colegas !
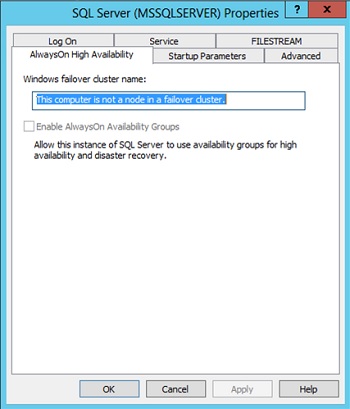
Lo debemos tener muy claro: Para habilitar AlwaysON, deberemos haber instalado previamente el Failover Cluster. Esto es requisito, es By Design, como podemos ver a continuación (un screenshot vale más que mil palabras ;-).
Es más, todos los servidores SQL que intervengan en nuestra solución AlwaysON deben ser miembros del mismo Failover Cluster (esto también es requisito de AlwaysON). Es decir, AlwaysON nos ofrece una solución de HA y DR dentro del mismo Cluster (within), y no entre diferentes Clusters (between), en cuyo caso deberíamos de utilizar otras soluciones como Database Mirroring (DBM).
Sin embargo, esto no debemos verlo como un simple e incómodo requisito, ni como un inconveniente. Todo tiene una explicación, y es que, por decirlo de algún modo, AlwaysON Availability Groups junta lo mejor de dos mundos: Failover Cluster y Database Mirroring. Y esto, se puede ver muy claramente en el caso de los Listener.
Entendido. Hasta aquí todo bien, dentro de lo esperado. Sin embargo, ahora empieza lo gracioso del asunto.
No es necesario utilizar un Almacenamiento Compartido (Shared Disk), aunque si lo deseamos podemos utilizarlo, incluso podemos tener un Cluster con Almacenamiento Asimétrico. OK. Y esto ¿cómo se come?
Pues muy fácil. Hasta ahora, con las versiones anteriores de SQL Server, siempre que montábamos un Failover Cluster, seguidamente realizábamos la instalación de SQL Server en Cluster (lo que se llama una FCI – Failover Cluster Instance). Esto era así, sí o sí. Pero ahora la historia ha cambiado, y quizás, este sea uno de los aspectos que pueda causar más confusión al empezar a conocer AlwaysON: Con AlwaysON, podemos realizar instalaciones de SQL Server en Cluster (FCI) y/o instalaciones de SQL Server Standalone, pero en todos los casos, debe estar el Failover Cluster instalado, y todos los servidores deben ser miembros del mismo Cluster.
Quizás, dicho todo esto, la confusión causada pueda ser incluso mayor. Pero no pasa nada. Eso se soluciona mostrando algún escenario de ejemplo:
- AlwaysON con dos servidores en CPDs distintos y almacenamiento local. En esta configuración, tendremos dos servidores miembros del mismo Failover Cluster, realizando una instalación de SQL Server 2012 Standalone sobre cada servidor, y configurando AlwaysON con una Replicación Síncrona con Failover Automático. Esta solución se la conoce como AlwaysON Availabity Groups for HA and DR.
- AlwaysON con cuatro servidores en dos CPDs distintos (2 + 2), y almacenamiento compartido local en cada CPD (es decir, un Almacenamiento Asíncrono, con dos redes SAN completamente independientes). En este caso, tendremos cuatro servidores miembros del mismo Failover Cluster, con dos instalaciones de SQL Server 2012 en Cluster (FCI) para conseguir HA, una en cada CPD, y cada instancia con un almacenamiento compartido propio y local al CPD al que pertenece. Configuraremos AlwaysON con una Replicación Síncrona y Failover Manual (para conseguir DR), siendo también posible la opción de Replicación Asíncrona (mejorando el rendimiento a consta de asumir una posible pérdida de datos en el DR). Esta solución se la conoce como FCI+AG (Failover Cluster Instance con Availability Groups).

- AlwaysON con tres servidores en dos CPDs distintos, 2 servidores en un CPD Principal con almacenamiento compartido y un tercer servidor en un CPD Secundario con almacenamiento local (Almacenamiento Asimétrico). En este caso tendremos una instalación de SQL Server 2012 en Cluster (FCI) sobre los dos Nodos que tienen el almacenamiento compartido para conseguir HA, así como otra instalación de SQL Server 2012 Standalone sobre el tercer Nodo. Configuraremos AlwaysON con una Replicación Síncrona con Failover Manual para conseguir DR. Esta solución se la conoce como Failover Cluster Instance for local HA and Availability Group for DR.
Almacenamiento Asimétrico
Tradicionalmente, siempre ha sido necesario la utilización de un Almacenamiento Compartido Simétrico para poder montar un Failover Cluster, es decir, todos los Nodos debían tener visibilidad sobre los mismos discos compartidos.
Sin embargo, como hemos comentado, con AlwaysON es posible montar un Failover Cluster con un Almacenamiento Compartido Asimétrico, en el que NO todos los Nodos tienen visibilidad sobre los mismos discos. Es decir, cada Disco Compartido puede ser presentado a sólo un sub-conjunto de los Nodos del Cluster.
Entonces ¿Es posible utilizar Almacenamiento Compartido Asimétrico al montar un Failover Cluster? Correcto y no. Me explico. Por defecto, ni en Windows Server 2008 R2 RTM, ni en versiones anteriores, es posible montar un Failover Cluster con Almacenamiento Asimétrico. Sin embargo, la instalación del SP1 de Windows Server 2008 R2 ó del correspondiente HotFix en Windows Server 2008, hace que sea posible montar un Failover Cluster con Almacenamiento Asimétrico, tal y como describe la siguiente KB: Hotfix to add support for asymmetric storages to the Failover Cluster Management MMC snap-in for a failover cluster that is running Windows Server 2008 or Windows Server 2008 R2
Realizado esto, podremos aprovecharnos del Almacenamiento Asimétrico en un Failover Cluster, teniendo en cuenta que para aquellos Discos Compartidos que sólo estén presentados a un sub-conjunto de los Nodos del Cluster, obtendremos un Warning como el siguiente al intentar Validar el Cluster: Disk with id XYZ is visible or cluster-able only from a subset of nodes
Además está recomendado que todas las Instancias involucradas en una instalación de AlwaysON Availability Groups, utilicen las mismas letras de unidad, incluso en el caso del Almacenamiento Asimétrico. En caso contrario, no podremos agregar ficheros a una BBDD replicada (deberemos quitar la réplica y volver a añadir la BBDD al Grupo de Disponibilidad).
En consecuencia, como podemos observar, el Almacenamiento Asimétrico es una de las claves de la tecnología AlwaysON de SQL Server 2012.
El Modelo de Quorum de Failover Cluster con SQL Server 2012 AlwaysON
Otro tema importante a tratar: El Modelo de Quorum. Las configuraciones de Failover Cluster con SQL Server 2012 AlwaysON, suelen implicar una configuración peculiar del Quorum. Pensemos en una solución FCI+AG (Failover Cluster Instance con Availability Groups), formada por dos FCIs, una en un DataCenter Principal y la otra en un DataCenter Secundario, con una Replicación Síncrona con Failover Manual. En este caso, al tener un número par de Nodos (4 Nodos), necesitaríamos añadir un árbitro (Witness), como Disco o un File Share, que proporcione un quinto voto de desempate, que permita que se produzca el síndrome del cerebro partido (Split Brain). Esto sería, a priori, una configuración normal y apropiada.
Pues estamos equivocados. Pensemos que en alguna ocasión el DataCenter Secundario no está disponible. En este caso, quedan tres de cinco Votos, por lo que el servicio se podrá seguir prestando (existe mayoría). Sin embargo, si en esta situación se produjese una indisponibilidad de uno de los Nodos existentes en el DataCenter Principal, tendríamos un serio problema, ya que perderíamos la mayoría (sólo tendríamos dos de cinco Votos), por lo que el servicio de Cluster de detendría.
Tenemos un problema, ya que el DataCenter Secundario está afectando a la forma de calcular la mayoría, lo que en algunas situaciones nos puede producir una indisponibilidad no deseada, un susto innecesario, y si tenemos SLAs hasta nos puede costar una penalización. ¿Qué podemos hacer?
Deberemos instalar en todos los Nodos del Failover Cluster el siguiente HotFix (require reinicio): A hotfix is available to let you configure a cluster node that does not have quorum votes in Windows Server 2008 and in Windows Server 2008 R2
Dicho HotFix, nos permitirá que podamos configurar cada Nodo del Cluster, para que cuente como un Voto para obtener la mayoría, o para que no cuente en absoluto. Volviendo a nuestro caso de ejemplo, después de aplicar el HotFix, configuraríamos los Nodos del DataCenter Secundario para no tener Voto, y añadiríamos un File Share Witness también en el DataCenter Principal, para tener así conseguir 3 Votos. Ahora, en caso de no estar disponible un Nodo del DataCenter Primario así como ninguno de los Nodos del DataCenter Secundario, se seguiría prestando el servicio, ya que estaría disponible aún un Nodo y el File Share Witness, por lo que tendríamos 2 de 3 Votos, existiendo mayoría, y ofreciéndose el servicio de Cluster y en consecuencia el servicio de SQL. Mola.

En caso de un desastre del DataCenter Principal, sería necesario realizar un cambio en la configuración del Cluster, de tal modo que los Nodos del DataCenter Secundario cuenten como Voto para formar mayoría. Además, sería necesario añadir un File Share Witness en el DataCenter Secundario, y configurar los Nodos del DataCenter Primario para que no tengan Voto.
Despedida y Cierre
Hasta aquí llega el presente artículo, en el cual hemos intentado ofrecer una primera visión de SQL Server 2012 AlwaysON Availability Groups (AG), incluyendo ciertos detalles relevantes relacionado con el Windows Server Failover Cluster (WSFC). Por último, antes de finalizar, aprovecho para incluir varios enlaces de interés, para quien desee ampliar esta información:
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.