La arquitectura de todo esto es bastante más sencilla de lo que parece. Tenemos una máquina de trabajo con nuestro Jupyter Notebook. La instalamos SparkMagic y lo configuramos para acceder a nuestro Cluster de Spark remoto, algo que realizará conectándose a través de la interfaz REST de Livy. Por lo tanto, necesitamos tener un Cluster de Spark con Livy instalado. Un caso de uso sería HDInsight (Hortonworks), donde por ejemplo en caso de desplegarlo en formato R Server (que incluye Spark también), tendríamos Livy en el Name Node y SparkMagic en el Edge Node.
Vamos a ver ahora un ejemplo muy sencillo. Tenemos un Cluster de Hadoop, Hive y Spark sobre unas Rasberry, como ya comentamos hace unos días. Sobre este Cluster de Spark instalamos Apache Livy, para habilitar esta interfaz REST que nos permita comunicarnos desde una máquina remota, como podría ser una estación de trabajo. Esto también lo vimos. Ahora queda sólo la parte que tenemos que hacer en la estación de trabajo.
Para ello, vamos a utilizar un pequeño portátil con Ubuntu, desde el cual nos queremos poder conectar a nuestro Cluster de Spark desde un Jupyter Notebook que ejecutemos localmente desde dicho portátil. Para ello, lo primero que tenemos que hacer es instalar Anaconda, por ejemplo en el home del usuario (ej: /home/guillesql/anaconda3). Esto no tiene mucho truco, la verdad.
Una vez instalado anaconda, vamos a instalar sparkmagic (con los comandos conda install y jupyter nbextension), crearemos los kernel de SparkMagic que necesitemos con el comando jupyter-kernelspc (importante utilizar la opción --user para evitar tener problemas de permisos, así como utilizar la ruta dependiendo de donde esté instalado sparkmagic, de aquí el pip show), habilitaremos la extensión de sparkmagic en Jupyter con el comando jupyter serverextension (este paso es opcional), y crearemos el fichero de configuración .sparkmagic/config.json.
|
conda install -c conda-forge sparkmagic
jupyter nbextension enable --py --sys-prefix widgetsnbextension
pip show sparkmagic
cd /home/guillesql/anaconda/lib/python3.6/site-packages
jupyter-kernelspec install sparkmagic/kernels/sparkkernel --user
jupyter-kernelspec install sparkmagic/kernels/pysparkkernel --user
jupyter serverextension enable --py sparkmagic
cd
mkdir .sparkmagic
wget https://raw.githubusercontent.com/jupyter-incubator/sparkmagic/master/sparkmagic/example_config.json
cp example_config.json config.json |
Realmente hay cuatro Kernels de Jupyter que podemos instalar, que según la documentación de GitHub del proyecto son:
jupyter-kernelspec install sparkmagic/kernels/sparkkernel
jupyter-kernelspec install sparkmagic/kernels/pysparkkernel
jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel
jupyter-kernelspec install sparkmagic/kernels/sparkrkernel |
Bueno, Bueno, ya casi está. Ya sólo queda editar el fichero .sparkmagic/config.json para poner los datos de conexión a nuestro Cluster de Spark, que en nuestro caso de ejemplo se limita a especificar la URL correcta (http://node01:8998) que corresponde al head node y al puerto por defecto de Apache Livy, que es donde tenemos instalado Livy y donde está escuchando. Hecho esto, abrimos nuestro Jupyter Notebook desde nuestro portátil, y a disfrutar.
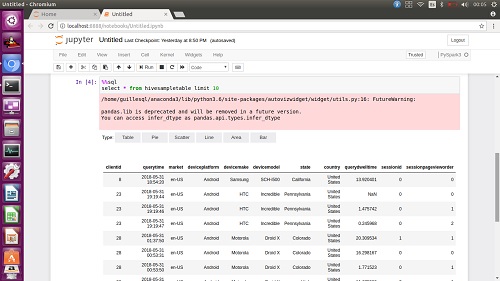
Lo primero, vamos a lanzar una consulta SQL contra el Hive remoto de nuestro Cluster, utilizando el atajo %%sql de SparkMagic (hay más atajos parecidos en SparkMagic, como %%help, %%info, etc), tal como se muestra en la siguiente pantalla capturada.
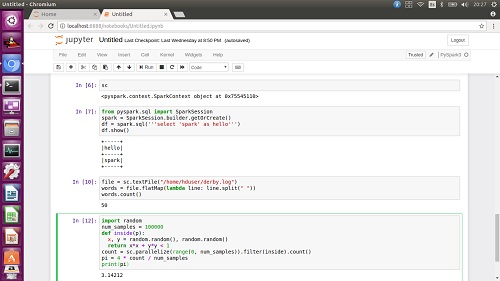
Haremos alguna prueba más, accediendo y utilizando el contexto de Spark de nuestro Cluster Spark remoto (ojo, sc.textFile accederá a los ficheros remotos, no a los de nuestra máquina local), comprobando que todo funciona correctamente.
Hasta aquí llega el presente artículo, en el que hemos querido mostrar la forma de ejecutar Jupyter Notebooks utilizando un Cluster Spark remoto con SparkMagic y Livy. Aprovecho para compartir algún enlace de interés, para quien desee ampliar información.
Poco más por hoy. Como siempre confío que la lectura resulte de interés.