Hoy vamos a dar otro pasito para ir completando nuestro Cluster de Hadoop, Hive y Spark sobre Raspberry, para que poco a poco, se vaya convirtiendo en un entorno que nos permita hacer más y más pruebas. En este caso, configuraremos el Metastore de Hive con MySQL, en lugar de Derby (como estaba inicialmente), para así permitir también la concurrencia y minimizar los problemas de corrupción.
Instalaremos MySQL con apt-get, y crearemos un usuario en MySQL para Hive.
sudo apt-get install mysql-server
sudo su
mysql -uroot
CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive';
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost';
FLUSH PRIVILEGES;
exit
exit |
Necesitaremos descargar un driver o conector Java para MySQL, y dejarlo copiado en el directorio lib de Hive (ej: /opt/hive/lib). El el siguiente trozo de código vemos un ejemplo, aunque también podríamos bajarlo directamente de MySQL, por ejemplo http://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-5.1.35.tar.gz. Seguidamente, crearemos el fichero hive-default.xml en /opt/hive/conf y lo editaremos.
wget -c http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.28/mysql-connector-java-5.1.28.jar -P /opt/hive/lib/
cd /opt/hive/conf/
vi hive-default.xml |
En el fichero hive-default.xml introduciremos la configuración de conexión a MySQL para Hive, de forma similar al siguiente ejemplo.
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration> |
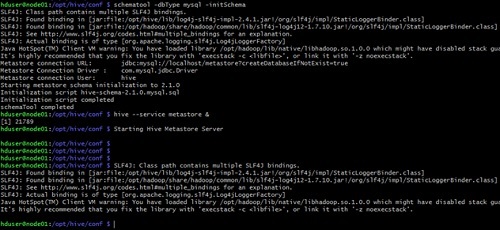
Inicializaremos el esquema de Hive y arrancaremos el servicio de metastore en segundo plano.
schematool -dbType mysql -initSchema
hive --service metastore & |
Acontinuación podemos ver un ejemplo de la salida de ejecución.
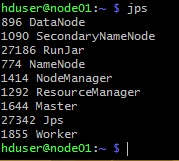
Con el comando jps podremos comprobar que el servicio de metastore está arrancado. En el siguiente pantallazo de ejemplo corresponde con el proceso RunJar.
El metastore de Hive, por defecto escucha en el puerto tcp 9083, por lo que podemos utilizar el comando netstat para comprobar que hay algún servicio escuchando en ese puerto, y cuál es el PID de dicho proceso (en nuestro caso de ejemplo es el 27186, el mismo que vemos en la salida del anterior comando jps) con un comando como netstat -putona | grep 9083
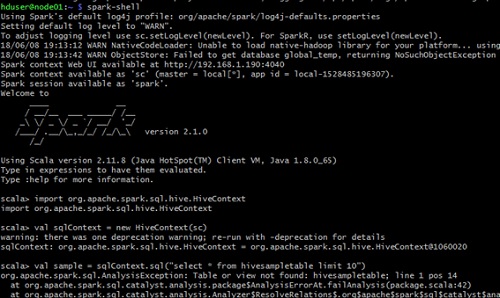
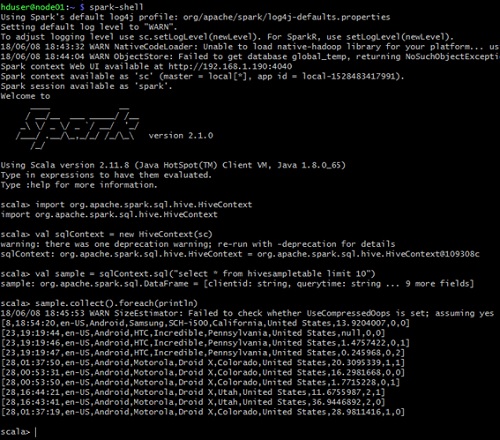
Ahora vamos a probar el acceso a Hive desde Spark, con la spark-shell, ejecutando un programa como el siguiente (en nuestro caso hemos creado previamente una tabla hivesampletable).
import org.apache.spark.sql.hive.HiveContext
val sqlContext = new HiveContext(sc)
val sample = sqlContext.sql("select * from hivesampletable limit 10")
sample.collect().foreach(println) |
Sin embargo, la ejecución acabará en error. Spark no es capaz de encontrar nuestra tabla de Hive.
Para solucionarlo, tendremos que compartir el fichero de configuración de Hive con Spark, algo que podemos hacer de forma elegante con un Soft Link. Lo mismo ocurrirá con el Driver de MySQL para que pueda acceder al metastore. Esto lo podemos conseguir con un par de comandos como los siguientes.
ln -s /opt/hive/conf/hive-site.xml /opt/spark/conf/hive-site.xml
ln -s /opt/hive/lib/mysql-connector-java-5.1.28.jar /opt/spark/jars/mysql-connector-java-5.1.28.jar |
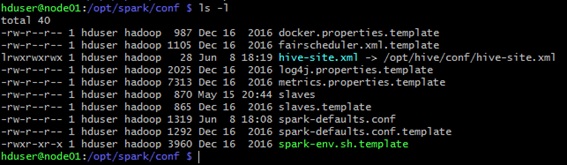
Ahora, si comprobamos el contenido del directorio de configuración de Spark, podremos ver claramente el Soft Link que acabamos de crear, tal y como se muestra en el siguiente pantallazo.
Ahora, vamos a ejecutar de nuevo el anterior programa desde la Spark Shell para comprobar el acceso a Hive desde Spark. Si. Ahora si funciona.
Con todo esto, el procedimiento de arranque de nuestro Cluster de Hadoop/Hive/Spark con Livy sobre Raspberry quedaría algo así.
start-dfs.sh
start-yarn.sh
start-master.sh
start-slaves.sh
hive --service metastore &
livy-server
jps |
Antes de acabar, aprovecho para recomendar la lectura de 1.1 Billion Taxi Rides with Spark 2.2 & 3 Raspberry Pi 3 Model Bs.
Poco más por hoy. Como siempre, confío que la lectura resulte de interés.